

זיכרון אג'נטי הוא אחד הנושאים המרכזיים בעולם ה-AI Agents כיום. כשאנחנו מדברים על סוכן חכם (Agent) שמסוגל לנהל שיחות ארוכות, לזכור העדפות, לעדכן עובדות ולפעול בצורה קוהרנטית לאורך זמן, אנחנו בעצם מדברים על מערכת זיכרון.
במדריך הזה נצלול לעומק הנושא: מה המשמעות של "זיכרון" בהקשר של סוכני AI, מדוע מודלי שפה לבדם אינם מספיקים, ואילו ארכיטקטורות ושיטות קיימות לבניית מערכת זיכרון אמיתית, מ-Simple Buffer ועד Self-Editing Memory.
נבין את ההבדל בין זיכרון עבודה לזיכרון ארוך טווח, נלמד כיצד Embeddings הופכים משמעות לגיאומטריה, נכיר את לולאת ה-RAG המלאה, ונדון ביישום לפרודקשן עם כל הסוגיות הנלוות: הפרדה בין משתמשים וארגונים (multi-tenancy), תקציבי latency, ומדיניות מידע (governance).
מה בעצם אומר "זיכרון" עבור סוכן AI?
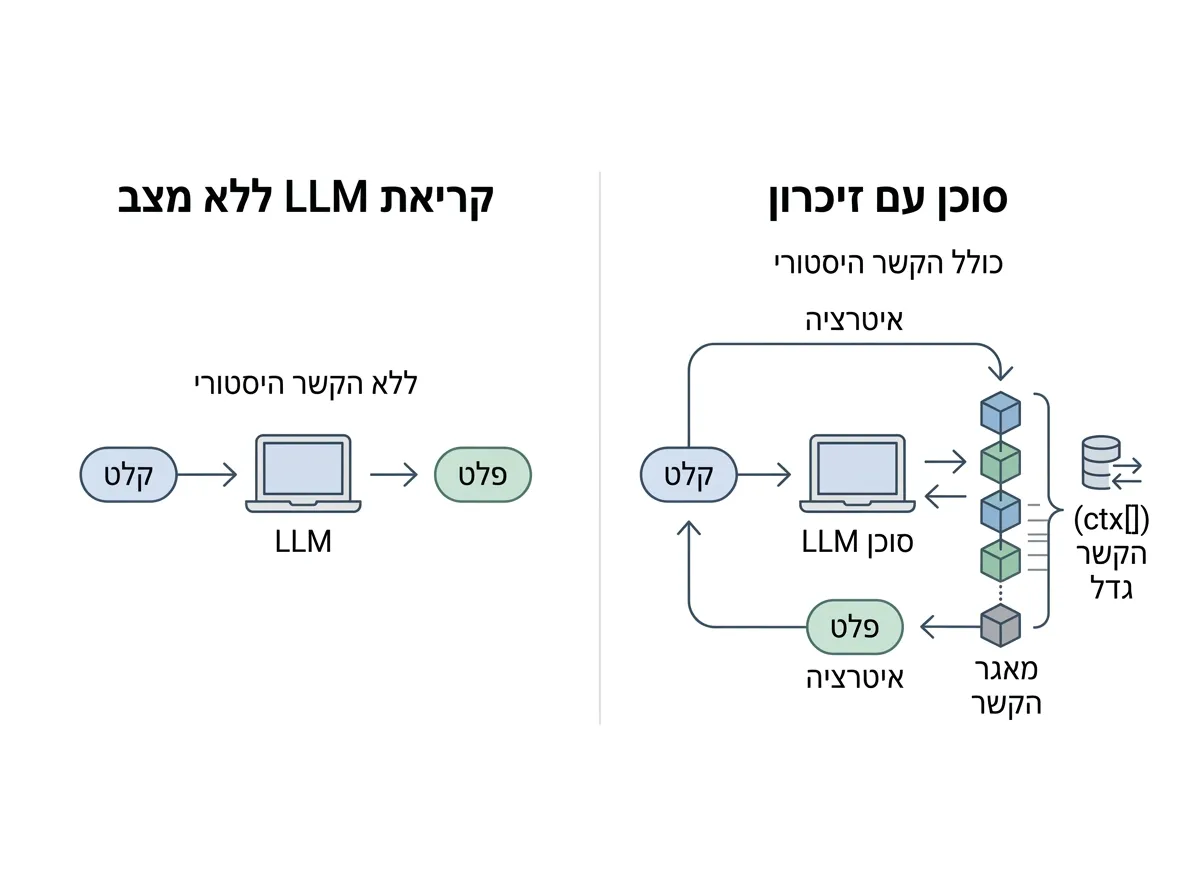
מודל שפה (LLM) כשלעצמו הוא חסר מצב (stateless). ״מוח מלאכותי״ קפוא ולא משתנה. אתם מזינים לו פרומפט, מקבלים תשובה, וברגע שהתגובה מסתיימת, המודל שוכח שאי-פעם היית קיים. אין "שיחה קודמת" שמתקיימת בתוך המשקולות של הרשת. כל קריאה ל-API היא עולם בפני עצמו.
סוכן (Agent), לעומת זאת, הוא הניהול (אורקסטרציה) שסביב המודל: לולאה שמחליטה איזה הקשר (Context) להזין לפרומפט בכל פעם מחדש. הזיכרון הוא החלק בלולאה הזו שנושא מידע קדימה מתור אחד לבא. כל מה שנדון בו במדריך הזה הוא תשובה שונה לאותה שאלה בדיוק: מה נכניס לפרומפט הפעם?
הבנת ההבדל הזה היא מהות העניין: קריאה סטטית ל-LLM רואה רק את הפרומפט הנוכחי שלה, ללא כל היסטוריה. סוכן עם זיכרון, לעומת זאת, רואה בכל קריאה את הפרומפט + הקשר שנצבר. בנק ההקשר הזה גדל עם הזמן, וניהולו הוא האתגר המרכזי.
כמו שנאמר: "סוכן מעצבן – שוכח הכל. סוכן מסוכן – זוכר לא נכון." שני הקצוות הם בעייתיים, ומשם מתחיל העיסוק בזיכרון נכון.
חלון ההקשר: הזיכרון הפשוט ביותר
לפני שנתחיל עם הדברים המורכבים, נכיר את סוג הזיכרון הפשוט ביותר שקיים: פשוט לדחוס את כל התמליל חזרה לפרומפט בכל תור. כל עוד הכל נכנס, למודל יש יכולת זכירה מושלמת.
המגבלה היא התקרה. לכל מודל יש חלון הקשר (Context Window) קבוע, מספר מקסימלי של ״טוקנים״ (לא בדיוק ״מילים״ – אלו ״יחידות משמעות סמנטית״) שהמודל יכול לראות בקריאה אחת. ברגע שהשיחה שלכם חורגת ממנו, אתם חייבים לוותר על משהו. המדיניות הנאיבית ביותר היא FIFO (דהיינו First In, First Out): זורקים את התור הכי ישן קודם.
אבל הבעיה היא שמדיניות FIFO היא הגרועה ביותר כשהתור שנזרק מכיל מידע קריטי. כמו למשל – שם המשתמש, או העדפה חשובה שהוזכרה בתחילת השיחה. תחשבו על מדרגות נעות: מידע חדש עולה מצד אחד, ומידע ישן נופל מהצד השני, ללא שום שיקול של חשיבות.
מערכות אמיתיות עושות טוב יותר: סיכום (Summarization), אחזור (Retrieval), דפדוף היררכי (Hierarchical Paging). נגיע לאלה בהמשך.
חשוב להפנים: "ההקשר הוא לא דאטה-בייס. אין Query Plan, אין אינדקס, אין בקרת גישה, אין TTL, אין פתרון קונפליקטים." זו פשוט רצועת טקסט שנכנסת לפרומפט. כל אינטליגנציה נוספת חייבת להיבנות מסביב.
זיכרון עבודה מול זיכרון ארוך טווח
בכל רגע נתון, הסוכן שלכם מתמודד עם שני דברים שונים מאוד. מצד אחד: השיחה החיה, התורות האחרונים, קריאות כלים ממתינות, וכל מה שהמודל חושב עליו באופן אקטיבי. מצד שני: כל מה שהוא אי-פעם החליט ששווה לשמור.
- זיכרון עבודה (Working Memory): חי, משתנה, בתוך הפרומפט. זו ה"לוח השרטוט" הנוכחי. הוא מכיל את ההודעות האחרונות, תוצאות כלים, וכל מה שצריך לחשיבה מיידית.
- זיכרון ארוך טווח (Long-term Memory): מוטמע (Embedded), עקבי, נשלף לפי דרישה. זה "הארכיון" שמחזיק עובדות, העדפות, ואירועים שנצברו לאורך זמן.
בעיניי, הדמיון בין מודל הזיכרון האג׳נטי – לזה האנושי, הוא מרתק.
ההעברה בין השניים היא המקום שבו רוב העיצוב המעניין קורה. מה מקודד לזיכרון ארוך טווח? מתי? באיזו רמת פירוט? במערכת אמיתית הסוכן מחליט בעצמו, בדרך כלל על ידי שאילת מודל נוסף: "האם התור הזה שווה שנזכור אותו?"
לדוגמה, מתוך שיחה חיה:
- "אני עובד במכללת Almaya" ← שווה לזכור (עובדה על המשתמש)
- "אני אוהב פרוגרסיב מטאל, וקאנטרי-רוק רך" ← שווה לזכור (העדפה)
- "אתה יכול למצוא בית קפה בקרבת מקום?" → לא שווה לזכור (בקשה חד-פעמית)
- "אני גר בירושלים" ← שווה לזכור (מיקום)
ארכיטקטורות מתקדמות יותר מרשות לסוכן גם לערוך את הזיכרון ארוך הטווח שלו תוך כדי פעולה, מה שנקרא Self-editing Memory.
כשכתיבות מתנגשות: מחזור חיים של זיכרון
זיכרון הוא לא בעיית אחסון. הוא בעיית מחזור חיים (Life Cycle): כתיבה, הזדקנות, החלפה (supersession), מחיקה, שכחה. שלוש גישות שונות מדגימות את הנקודה:
נניח שמגיעות שלוש אמירות מהמשתמש:
- "אני גר בפתח תקווה"
- "אני עובר למושב מגשימים בחודש הבא"
- "מספר כרטיס האשראי שלי הוא 1234-5678-9012-3456"
גישה נאיבית – הוספה (Naive Append): שומרת הכל כפי שהוא. תוצאה: דליפת PII (מספר כרטיס האשראי נשמר) ויצירת סתירות (שני יישובים שונים ללא הבהרה).
גישה נאיבית – דריסה (Naive Overwrite): מחליפה את העובדה הישנה בחדשה. תוצאה: אובד ההקשר הזמני. הסוכן לא יכול לענות "איפה המשתמש גר בעבר?"
גישה מנוהלת (Governed): שומרת את העובדה החדשה כפעילה ("המשתמש גר במגשימים, תקף מהחודש הבא"), מסמנת את הישנה כמוחלפת (superseded) אך שומרת אותה לצורך חשיבה זמנית, ומונעת את כניסת מספר כרטיס האשראי למאגר (PII filter מזהה את הדפוס ועושה redaction).
הגישה המנוהלת היא היחידה שמתאימה לפרודקשן. היא ידידותית לביקורת (audit-friendly), מודעת לזמן (time-aware), ומגנה על פרטיות.
Embeddings: הפיכת משמעות לגיאומטריה
Embedding הוא וקטור, רשימת מספרים, שנוצרת על ידי העברת טקסט דרך רשת נוירונית שאומנה למטרה אחת: לשים משמעויות דומות קרוב זו לזו במרחב מתמטי. מעין מערכת צירים מרובת ממדים. Embeddings אמיתיים חיים בדרך כלל במאות עד אלפי ממדים; ה-Embeddings של OpenAI כיום מגיעים ל-1,536 או 3,072 ממדים.
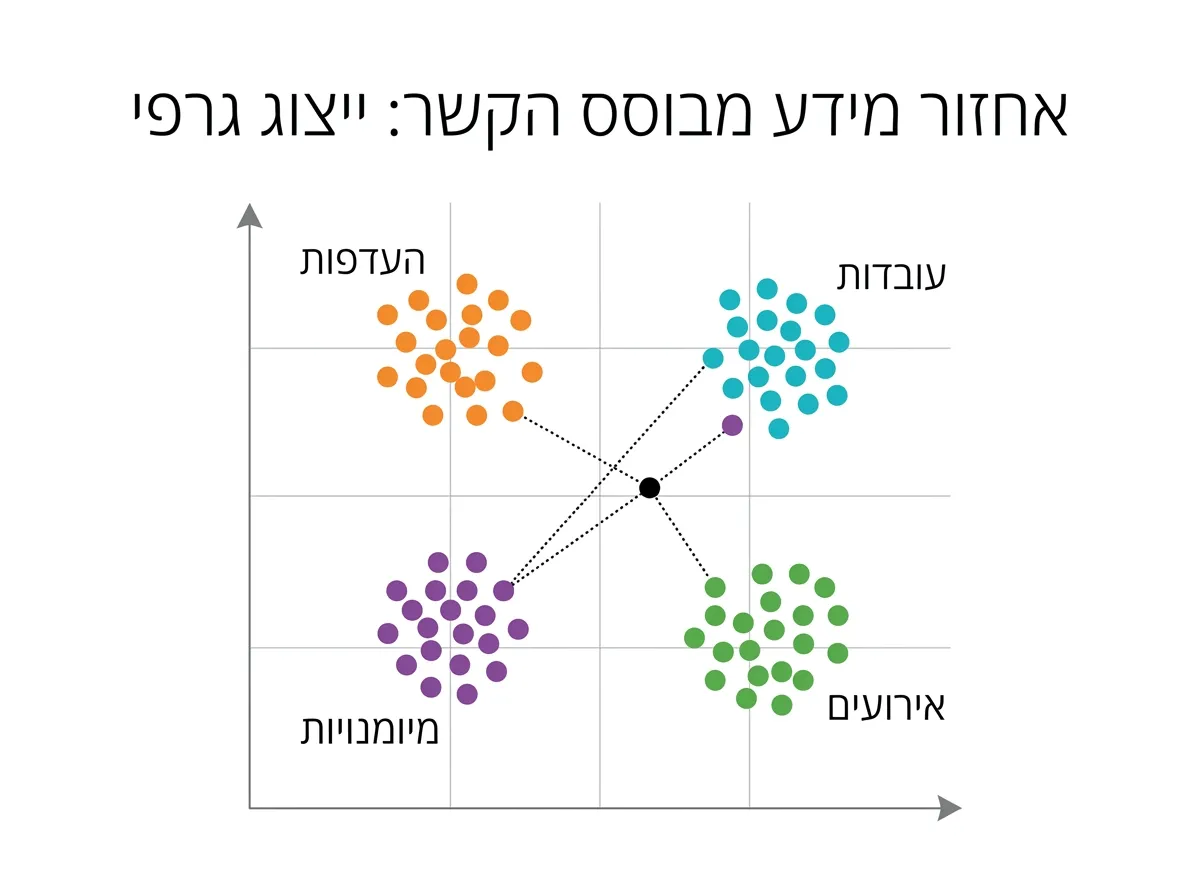
מה הרעיון? כשאתם שומרים זיכרון של משתמש (למשל "המשתמש אוהב לשמוע פרוגרסיב מטאל וקאנטרי-רוק"), אתם מריצים את הטקסט דרך מודל Embedding ומקבלים וקטור. כשמגיעה שאלה חדשה ("מה המשתמש אוהב לשמוע?"), גם אותה ממירים לוקטור, ואז מחפשים את הנקודות הכי קרובות.
המרחק נמדד באמצעות Cosine Similarity: ככל שהזווית בין שני וקטורים קטנה יותר, כך הם דומים יותר מבחינת משמעות. הטריק הזה עובד באותה צורה בדיוק ללא קשר למספר הממדים, וזו הסיבה שהוא סקלבילי. שיטה אחרת למדידת מרחק היא ״מרחק אוקלידי״ (זוכרים משפט פיתגורס? אז כזה, בהרבה ממדים).
לדוגמה, אם במאגר הזיכרון יש 20 רשומות על משתמש (העדפות, עובדות, מיומנויות, אירועים), והשאלה היא "מה המשתמש אוהב לשמוע?", התוצאות המובילות יהיו:
- "המשתמש אוהב פרוגרסיב מטאל וקאנטרי רוק" (similarity: 0.999)
- "המשתמש קורא מאמרים על חוש השמיעה" (similarity: 0.996)
- "המשתמש מכיר את כל השירים של הביטלס" (similarity: 0.992)
שימו לב: תוצאות סמנטיות, לא התאמה מילולית. המילה "לשמוע" לא מופיעה בהכרח בכל הרשומות, אבל המשמעות קרובה.
ארבעה סוגי זיכרון, סוכן אחד
מדעי המוח והפסיכולוגיה הקוגניטיבית מסווגים את ה"זיכרון" כבר מעל מאה שנה. מערכות אג׳נטיות מודרניות משתמשות באותו אוצר מילים, כי ההבחנות באמת שימושיות: לכל סוג זיכרון יש צורה שונה, כלל כתיבה שונה, ואסטרטגיית שליפה שונה.
-
זיכרון אפיזודי (Episodic Memory):
- מה קרה, ומתי. יומן מסודר בזמן של אינטראקציות עבר.
- כל רשומה מכילה חותמת זמן (
when). - אחזור (שליפה) בדרך כלל לפי רלוונטיות (recency): "על מה דיברנו זה עתה?"
- דוגמה: "ביום שלישי המשתמש שאל על ג׳ון מאייר."
- כך עובד פיצ'ר ה-Memory של ChatGPT: זכירה עקבית בין סשנים.
-
זיכרון סמנטי (Semantic Memory):
- עובדות ויחסים. מידע מובנה על העולם או על המשתמש.
- דוגמה: "המשתמש גר בנחלאות, ירושלים."
- RAG שולף את התיאור המלא מהקטלוג.
-
זיכרון פרוצדורלי (Procedural Memory):
- מיומנויות וכלים נלמדים. ידע על איך לעשות דברים.
- דוגמה: כלי
course_detailשמופעל כשצריך מידע חי שקטלוג הקורסים עדיין לא מכיל.
-
זיכרון עבודה (Working Memory):
- לוח השרטוט הנוכחי. System prompt + עובדות שנשלפו + תוצאת כלי + ההודעה החדשה, כולם יושבים בהקשר הפעיל, וה-LLM עונה משם.
דוגמה לשילוב כל הארבעה בתור אחד: מבקר ניגש לאתר של מכללה ואומר: "ספר לי עוד פרטים על הסדנה שהזכרת קודם."
- אפיזודי: חיפוש וקטורי מוצא את השיחה הקודמת שבה הסדנה הוזכרה.
- סמנטי: RAG שולף את התיאור המלא של הסדנה מהקטלוג.
- פרוצדורלי: כלי course_detail נקרא עבור כל מידע חי שהקטלוג חסר.
- עבודה: הכל מורכב לפרומפט אחד, וה-LLM עונה.
תור אחד, ארבעה מאגרים. הסוכן זוכר (אפיזודי), יודע (סמנטי), יכול לעשות (פרוצדורלי), ועוקב אחר השרשור החי (עבודה) מבלי שהמשתמש מרגיש את התפרים.
לולאת ה-RAG המלאה: צעד אחר צעד
כל מה שדיברנו עליו עד כה מתחבר כאן. RAG (Retrieval-Augmented Generation) היא הלולאה שרוב הסוכנים בפרודקשן מריצים בכל תור: מקבלים את ההודעה, מקודדים, מוצאים זיכרונות דומים, מכניסים לפרומפט, מייצרים תשובה, ורק כשהמשתמש הציג מידע חדש, מחליטים מה שווה לזכור.
- User Query – הודעת משתמש: הודעה חדשה מגיעה. היא נושאת גם שאלה וגם עובדה חדשה על המשתמש.
- Embed Query – הטמעת השאילתה: ההודעה עוברת דרך מודל Embedding ומומרת לוקטור.
- Vector Search – חיפוש וקטורי: הוקטור מושווה למאגר הזיכרונות.
- Retrieve – שליפת top-k: ה-k הזיכרונות הרלוונטיים ביותר נשלפים.
- Compose Prompt – הרכבת פרומפט: הזיכרונות הנשלפים + ההודעה החדשה מורכבים לפרומפט שלם.
- Generate – תשובת LLM: המודל מייצר תשובה על בסיס הפרומפט המורכב.
- Govern – בקרת מידע חדש: האם ההודעה הכילה מידע חדש? האם הוא בטוח לשמירה? האם הוא מחליף עובדה קיימת?
- Update Memory – עדכון הזיכרון: אם עבר את שלב הבקרה, המידע נכתב למאגר.
כל שלב בלולאה הוא מקום שבו אפשר להשקיע "תקציב הנדסי": Embeddings טובים יותר, אחזור חכם יותר, דחיסת פרומפט, ממשלה מחמירה יותר. כולם אותו Pipeline, רק עם יותר תשומת לב בשלב מסוים.
טריקים לפרודקשן: HyDE ו-Reciprocal Rank Fusion
שני טריקים שמשפרים משמעותית את איכות האחזור במערכות אמיתיות:
HyDE (Hypothetical Document Embeddings):
שאלה ותשובה הן צורות שונות. הטמעת השאלה ישירות לעתים קרובות מפספסת מסמכים שמכילים את התשובה. HyDE מבקש מה-LLM לייצר תשובה היפותטית קודם, מטמיע אותה, ואז מחפש. התשובה המזויפת לא צריכה להיות נכונה, רק להיות בצורה דומה למטרת האחזור.
דוגמה:
- שאילתת המשתמש: "לאן המשתמש הולך בדרך כלל בסופי שבוע?"
- תשובה היפותטית מ-LLM: "המשתמש הולך לטיולים בקניונים בסופי שבוע."
- Embed: מטמיעים את התשובה ההיפותטית (לא את השאלה)
- תוצאת חיפוש: "המשתמש הולך לטיול בקניונים בימי שבת." (התאמה מצוינת!)
RRF (Reciprocal Rank Fusion):
במקום לבחור retriever יחיד, מריצים כמה במקביל ומאחדים את הדירוגים. Dense embeddings מצוינים לפרפרזה וכוונה, חיפוש לקסיקלי (BM25) מנצח על מזהים מדויקים וטוקנים נדירים, Knowledge Graph תורם תשובות מבניות וזיכרון אסוציאטיבי. מריצים את שלושתם ומאחדים עם נוסחת RRF:
# RRF formula
score(doc) = sum(1 / (k + rank_i)) for each retriever i
# where k is typically 60
התוצאה: דירוג ממוזג שמנצל את החוזקות של כל retriever מבלי להסתמך על אחד בלבד.
תהליך השליפה: Pipeline ולא Lookup
אחזור בפרודקשן הוא Pipeline קטן שרץ בכל תור. לדלג על שלב כלשהו זה בדרך כלל אומר שדברים נשברים. הנה הרצף המלא:
- Need Detection (האם בכלל צריך?): קריאה ל-retrieval אינה חינמית. אם המודל יכול לענות "בעצמו", מדלגים. למשל, "תרגם Hello ליפנית" לא דורש זיכרון.
- Query Rewrite (שכתוב השאילתה): שיפור הניסוח לפני החיפוש.
- Dense Search (חיפוש צפוף): חיפוש סמנטי מבוסס embeddings.
- Sparse Search (BM25): חיפוש לקסיקלי מסורתי.
- Graph Walk: מעבר על Knowledge Graph.
- Fuse (מיזוג): איחוד הדירוגים עם RRF.
- Rerank (דירוג מחדש): מודל Reranker שמדרג את התוצאות הממוזגות.
- Filter (סינון): הרשאות (permission scope) ותוקף זמני (temporal validity).
- Pack (אריזה): הכנסת התוצאות לפרומפט בפורמט מובנה.
הבאגים המעניינים הם לא "הסוכן שכח". הם דברים כמו: retriever שמייצר זיכרון שנכון טכנית – אבל מיושן ולא רלוונטי להקשר, או בהיקף שגוי, או תקין בפני עצמו אבל סותר שורה אחרת שנשלפה. Filters ו-Rerank קיימים בדיוק למקרים האלה.
שש ארכיטקטורות, שישה Tradeoffs
רוב הסוכנים בפרודקשן משלבים כמה ארכיטקטורות: Vector Store לזכירה סמנטית, Graph לעובדות מובנות, שכבת Governance שמטפלת ב-supersession ו-PII. הנה סקירה מהירה:
-
Simple Buffer:
- פשוט שומרים את כל התמליל בפרומפט.
- אין יכולת Scale, אין מבנה, אין ממשלה. מתאים רק לדמואים.
-
Rolling Summary:
- מסכמים את השיחה באופן מתגלגל.
- Scale בינוני, אבל מאבדים פרטים ואין מבנה.
-
Vector Store:
- מטמיעים כל זיכרון, שולפים top-k לפי דמיון.
- ברירת המחדל עבור סוכני RAG. קיבולת כמעט בלתי מוגבלת, זכירה סמנטית, Tooling בוגר.
- חולשות: איכות האחזור תלויה במודל ה-Embedding, אין מושג של יחסים או זמן ללא metadata נוסף; קל "להרעיל" אם כתיבות לא שמורות.
-
Knowledge Graph:
- מבנה מלא של ישויות ויחסים.
- תומך ב-supersession באופן טבעי.
- מורכב יותר לתחזוקה.
-
Hierarchical (MemGPT style):
- מחלק את הזיכרון לשכבות (כמו RAM ודיסק קשיח במחשב).
- ה-Agent "מדפדף" מידע פנימה והחוצה מההקשר.
- Scale טוב, אבל דורש ניהול מורכב.
-
Self-Editing (Letta style):
- הסוכן יכול לערוך, לעדכן ולמחוק את הזיכרון שלו עצמו.
- תומך ב-supersession באופן טבעי.
- הגישה החזקה ביותר, אבל גם הכי מסוכנת: מה קורה כשהסוכן "עורך" בטעות?
אנו במכללה, עוסקים בטכניקות הללו תוך כדי בניה מעשית בסדנת Claude Code – Inside Out – היכרות עמוקה עם סוכני Coding, ״מבפנים״.

זיכרון רב-סוכני: גרף ולא מאגר
סוכן בודד רק צריך לענות "מה אני זוכר?". ברגע שיש לכם צוות סוכנים, השאלה הופכת ל: איזה סוכן זוכר איזו עובדה, בשם מי, ומי עוד יכול לקרוא אותה. הזיכרון הופך לגרף של מאגרים עם היקפים (scopes), הרשאות, וכללי הפצה.
עקרון המפתח: זיכרון פרטי כברירת מחדל, זיכרון משותף באופן מפורש. הערת מחקר שסוכן Researcher רושם לעצמו לא צריכה להגיע לערוץ הפרויקט. כתיבה חוצת-היקפים צריכה להיות פעולה מכוונת, עם מדיניות ברורה.
שש מלכודות בזיכרון משותף:
- דליפה בין משתמשים (Cross-user leakage): סוכן Researcher שמר "המשתמש מעדיף מתכונים טבעוניים" בזיכרון פרויקט. בסשן הבא, משתמש אחר מקבל הצעות טבעוניות מהאוויר. מניעה: פילטרים של tenant_id + user_id על כל קריאה.
- שיתוף יתר (Over-sharing): מידע שלא רלוונטי מופץ לכל הסוכנים.
- הפצת רעל (Poison propagation): עובדה שגויה שנכתבת למאגר משותף מתפשטת לכל הצוות.
- החלטות סותרות (Conflicting decisions): שני סוכנים כותבים עובדות סותרות.
- Playbook מיושן (Stale playbook): הנחיות שהשתנו לא מתעדכנות בכל הסוכנים.
- אובדן ייחוס (Attribution loss): לא ברור מי כתב מה ומתי.
פריימוורקים כמו AutoGen, Claude Agent SDK, CrewAI, ו-LangGraph נותנים את ה״אינסטלציה״ הזאת (checkpoints, persistence, message-passing primitives). אבל אף אחד מהם לא קובע את המדיניות (governance) בשבילכם. Scope, Policy, Ingestion, ו-Evaluation עדיין שלכם.
בפרודקשן: זיכרון הוא מערכת
הוספת זיכרון למוצר אמיתי היא לא "התקן Vector DB". אתם צריכים API, נתיבי קריאה וכתיבה נפרדים, הוצאת פעולות לעבודה ברקע (background extractors), הפרדת משתמשים-ארגונים, תקציבי latency, observability, ותוכנית ליום שבו תשנו את מודל ה-Embedding שלכם.
ארכיטקטורת הייחוס:
שני שירותים, מופרדים בחדות: Agent Runtime על נתיב הבקשה, ו-Memory Service כ-side-quest. כמה Workers ברקע עושים את העבודה האיטית והיקרה: חילוץ, סיכום, Embedding מחדש, דעיכה, ללא חסימת המשתמש וה-UI.
נתיב הקריאה (Read Path):
User/App → Auth + Scope → Agent Runtime → Memory Service (Dense + BM25 + Graph) → Fuse + Rerank → Pack Context → LLM
שלוש שכבות אחסון:
- Hot: עובדות פעילות של משתמש/פרויקט. KV cache או In-memory. נקרא בכל תור. Redis / שורת SQL.
- Warm: אפיזודות אחרונות, העדפות. Vector + Full-text index. נקרא לפי צורך. Qdrant / pgvector.
- Cold: יומן אירועים גולמי, סשנים בארכיון. Object Storage. נקרא ל-backfill / audit. S3 / append-only log.
תקציב Latency:
אחזור זיכרון רץ בתורות, אז כל מילישנייה על הנתיב היא לייטנסי. האופטימיזציות המעניינות הן: דילוג על retrieval כשלא צריך, caching של top-N עובדות למשתמש ב-KV, והרצת retrievers שונים (dense, sparse, graph) במקביל ולא ברצף. תקציב יעד סביר: 800ms כוללני.
Memory API מינימלי:
POST /memory/events– הוספת אירועים גולמיים. תור כתיבה מטפל ב-dedup ו-indexing באופן אסינכרוני.POST /memory/search– אחזור היברידי עם scope, זמן, ו-top_k. השרת אוכף פילטרים מה-JWT.DELETE /memory/{id}– שכחה. מתפשטת לאינדקסים נגזרים. מחיקה היא אירוע audit בפני עצמו.
שום דבר מזה לא קסם ולא ״וואו״. זו אותה ארכיטקטורה שהייתם בונים לכל מוצר retrieval. הלקח הוא פשוט שזיכרון אג'נטי הוא מוצר retrieval, לא feature flag. התייחסו אליו ככה, והשאר יבוא.
כמו שנאמר: "ניהול זיכרון היא מה שמפריד בין דמו חד-פעמי לסוכן פרודקשן."
לסיכום: בניית זיכרון אג'נטי משלכם
כל מה שנכתב במדריך הזה מצטמצם בסופו של דבר לסט קטן של "ידיות כוונון". בחרו backend (Buffer, Vector, Hierarchical, Self-editing), הגדירו מגבלות (גודל חלון הקשר, k לאחזור), והפעילו את הטכניקות שאתם סומכים עליהן (HyDE, RRF, Governance Gate).
כמה טיפים מעשיים להתחלה:
- התחילו פשוט: Vector Store בסיסי עם top-3 retrieval ו-governance gate. זה מספיק ל-80% מהמקרים.
- בדקו עם "שאלת הסתירה": שלחו עובדה, ואז שלחו עובדה סותרת. האם הסוכן מטפל נכון? האם הישנה מסומנת כ-superseded?
- בדקו עם "שאלת ה-PII": שלחו מספר כרטיס אשראי. האם הוא חודר למאגר? אם כן, יש עבודה לעשות.
- מדדו latency מההתחלה: הגדירו תקציב (800ms) ועקבו אחריו. retrieval שלוקח 2 שניות הורס את חוויית המשתמש.
- תכננו ליום שינוי ה-Embedding: כשמחליפים מודל embedding, צריך re-embedding של כל המאגר. תכננו לזה מראש.
זיכרון אג'נטי הוא לא פיצ'ר. הוא מערכת. הוא ההבדל בין צ'אטבוט שמתחיל מאפס בכל שיחה, לבין סוכן שמכיר אתכם, מתפתח איתכם, ומשתפר עם הזמן. בנו אותו כמוצר, ותקבלו תוצאות של מוצר.
בהצלחה!