

איך הכל התחיל?
דמיינו לעצמכם את השנה 1961. מחשבים פשוטים (של 4 פעולות חשבון) הם מפלצות ענקיות שמילאו חדרים שלמים, האינטרנט עדיין לא נולד, והמילה "בינה מלאכותית" הומצאה לראשונה רק לפני 5 שנים, ונשמעת כמדע בדיוני טהור. ובדיוק אז, פרופסור צעיר באוניברסיטת קיימברידג' בשם דונלד מיצ׳י (Donald Michie) חשב על רעיון – לבנות מכונה שיכולה ללמוד בעצמה לשחק איקס-עיגול.
אבל הוא לא השתמש במחשב.
במקום זה, הוא השתמש ב-304 קופסאות גפרורים, חרוזים צבעוניים, וכמות אדירה של סבלנות.

הרעיון המטורף שעבד
מיצ׳י, שהיה מתמטיקאי מבריק וחלוץ בתחום הבינה המלאכותית, הבין משהו פשוט אבל מהפכני: לימוד-מכונה זה לא קסם. זה לא דורש מחשבי-על (שאפילו המושג עוד לא היה בנמצא…) או אלגוריתמים מסובכים. זה בעצם עניין של ניסיון וטעייה, זיכרון, ויכולת להסיק מסקנות מהצלחות וכישלונות.
אז הוא בנה את MENACE או "Machine Educable Noughts And Crosses Engine". "מכונת משחק איקס-עיגול, הניתנת לאימון" בתרגום חופשי.
השם נשמע מפחיד, אבל המציאות הייתה הרבה יותר מקסימה.
היא מבוססת על שיטת לימוד מתחום הפסיכולוגיה – Reinforcement learning, לימוד דרך התנסות אישית, תוך מתן פרסים על הצלחות, ו״קנסות״ על כשלונות.
לימים, בתחום ה Machine Learning, השיטה נודעה כ ״Q-Learning״.

למה דווקא קופסאות גפרורים?
בשנות השישים, זמן מחשב היה יקר מזהב. מיצ׳י רצה להוכיח שהעקרונות של לימוד-מכונה פשוטים מספיק כדי שאפשר ליישם אותם בכלים הכי בסיסיים שיש. הוא רצה להראות שמאחורי כל האלגוריתמים המורכבים, מסתתרת לוגיקה פשוטה שכל אחד יכול להבין.
וכך נולדה אולי המכונה הכי מקסימה בהיסטוריה של הבינה המלאכותית – מכונה שלא דורשת חשמל, לא מתקלקלת, ואפשר לראות בדיוק איך היא "חושבת".
כל קופסת גפרורים ייצגה מצב משחק אפשרי וחוקי של איקס-עיגול. סה״כ 304 קופסאות ל 304 מצבים.
בתוך כל קופסה היו חרוזים צבעוניים, כאשר כל צבע ייצג את אחד התאים בלוח המשחק. המכונה "למדה" על ידי שינוי כמות החרוזים בקופסא, בהתאם להצלחות וכישלונות לאורך אלפי משחקים.
פשוט? בהחלט. גאוני? ללא ספק.
הלקח הגדול
מה שמיצ׳י הוכיח ב-1961 רלוונטי היום יותר מתמיד: לימוד-מכונה זה לא רק על עוצמת חישוב או אלגוריתמים מתוחכמים. זה על הבנת העקרונות הבסיסיים של איך מכונה יכולה ללמוד מניסיון, וזה (אולי באופן לא מפתיע) מקביל לאיך שאנחנו, בני האדם, לומדים מנסיון חיים ישיר.
MENACE הצליחה להפוך מחסרת כל הבנה במשחק, לשחקנית מיומנת, כמעט ללא הפסד – וכל זה בלי שורת קוד אחת.
עכשיו, בואו נצלול לפרטים הטכניים ונראה איך בדיוק המכונה המדהימה הזו עבדה…
איך זה עובד?
מצב התחלתי
בבסיס המערכת נמצאות 304 קופסאות גפרורים, כל אחת מייצגת מצב משחק אפשרי וחוקי. בתוך כל קופסא – חרוזים צבעוניים המייצגים את המקומות האפשריים להנחת העיגול. (אנחנו מניחים ש MENACE תמיד מתחילה משחק, והיא תמיד מייצגת את העיגול).
כל צבע – ממופה למיקום אפשרי להנחת העיגול באופן הבא:

שימו לב שלא כל הצבעים יופיעו בכל קופסא. לדוגמא קופסא המייצגת מצב לוח בו התא ה״כחול״ כבר תפוס – בקופסא זו לא יהיה צבע כחול.
כמו״כ – בכל קופסא, מספר החרוזים מכל צבע חוקי היה כמספר התורים שנשארו עד סיום המשחק.
לדוגמא:
- בקופסא המייצגת לוח ריק – היו 4 חרוזים מכל צבע חוקי.
- בקופסא המייצגת מצב לוח בו נותרו 3 תורים – יהיו רק 3 חרוזים מכל צבע חוקי.
- וכן הלאה – עד שבקופסא בה נותן מהלך יחיד – יהיה רק חרוז אחד מכל צבע חוקי.
מהלך האימון
תהליך האימון כולל ביצוע אלפי משחקים, בהם MENACE מתופעל ע״י אדם (משחק את תפקיד העיגול) ובצד השני – אדם אחר המשמש כיריב ומשחק את תפקיד האיקס.
בכל תור – המפעיל ניגש לקופסת הגפרורים המייצגת את מצב הלוח הנתון, ובוחר באופן אקראי באחד החרוזים שיש בה.
בהתאם לצבע החרוז שהוגרל – מסמנים עיגול בתא המתאים על לוח המשחק, ובוחרים בקופסא הבאה, המייצגת את מצב הלוח החדש.
לאחר שהיריב שיחק את התור שלי (בתפקיד האיקס), שוב נבחר חרוז אקראי מתוך הקופסא המתאימה, וכן הלאה עד סיום המשחק – ניצחון, הפסד, או תיקו.
מבלבל? גם אותי.
בואו נעשה משחק לדוגמא:
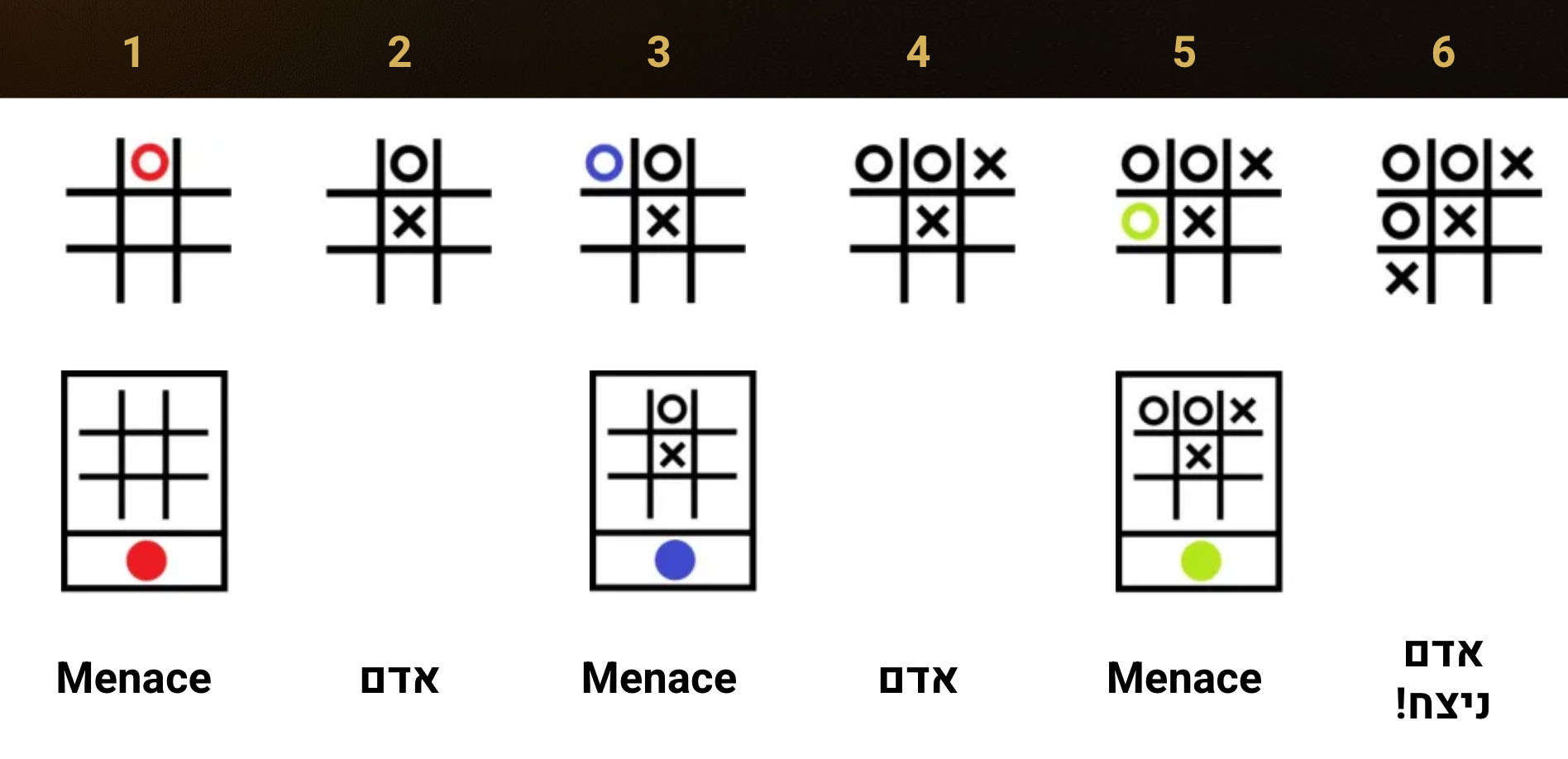
מהלך המשחק:
- מתחילים מקופסת הלוח הריק, Menace מתחיל ובוחר אקראית את החרוז האדום. מסומן עיגול בשורה העליונה, במרכז.
- האדם מסמן X בתא המרכזי.
- מתוך הקופסא המייצגת את מצב הלוח הנוכחי, Menace בוחר אקראית את החרוז הכחול ומסומן עיגול בשורה העליונה משמאל.
- האדם מסמן X בפינה העליונה מימין.
- מתוך הקופסא המתאימה – Menace בוחרת אקראית בחרוז הירוק, ומסומן עיגול בשורה האמצעית משמאל.
- האדם מסמן איקס בפינה התחתונה משמאל ומנצח.
- Menace הפסיד.
משוב – Reinforcement Learning
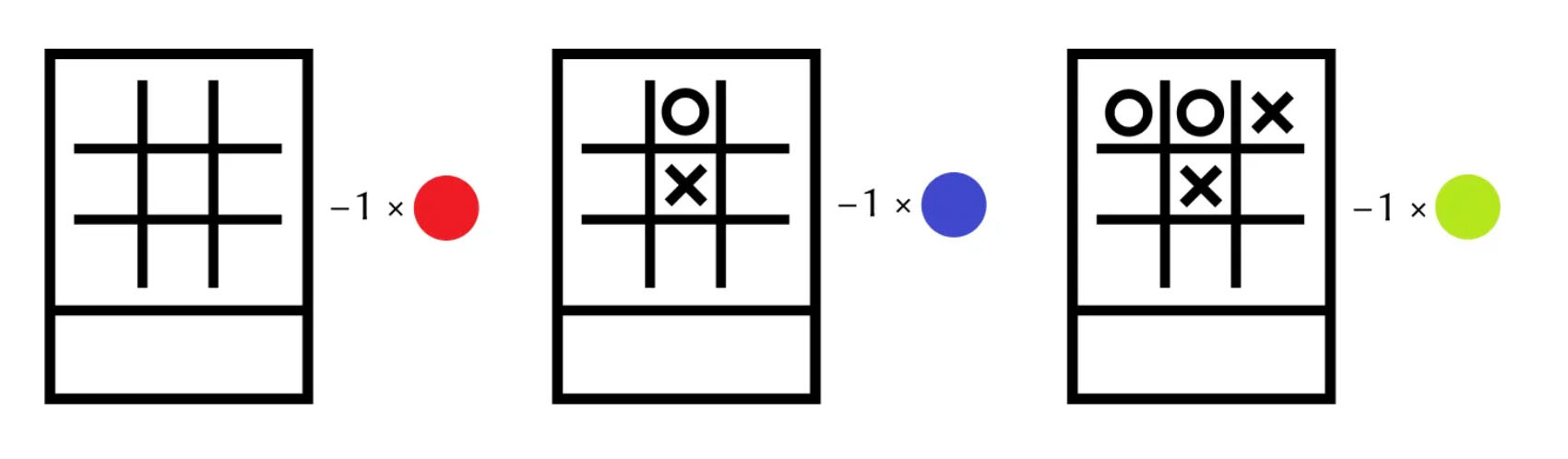
שיטת הלימוד Reinforcement Learning מעניקה ״פרס״ על הצלחה, ו״קנס״ על הפסד. במקרה שלנו Menace הפסיד – ועליו לקבל ״קנס״.
מה זה אומר תכל׳ס?
המשמעות של ההפסד היא, שכל הבחירות ש Menace ביצע במהלך המשחק – היו שגויות, ולכן הקנס הוא – שנסיר חרוז אחד מתוך הצבע שהוגרל בכל אחת מהקופסאות שהשתתפו במשחק.
כלומר:
- מהקופסא הראשונה נסיר את החרוז האדום.
- מהקופסא השניה נסיר את החרוז הכחול.
- מהקופסא השלישית נסיר את החרוז הירוק.
איך כל זה משפיע על הלימוד?
פשוט – במשחקים הבאים, כאשר נגיע שוב למצב הלוח המסוים (כלומר – לאותה קופסא), הסיכוי ש Menace יבחר שוב בחרוז מאותו הצבע שהוביל אותו להפסד – יילך ויקטן.
באופן דומה – על כל משחק ש Menace ניצח – הקופסאות הרלוונטיות ״יזכו״ בחרוז נוסף מהצבעים שנבחרו, כך שבפעמים הבאות, הסיכוי לבחור בצבעים הללו דווקא יגדל.
זה מהות תהליך האימון דרך Reinforcement Learning.
מודל Q-Learning
לאחר ביצוע אלפי משחקים, מספר החרוזים בכל קופסא מתקבע על מספר מסויים – ההסתברות שהמהלך יוביל את Menace לניצחון.
וכיוון שבמשחק איקס עיגול – מספר האפשרויות לכל מהלך הוא די מצומצם, ניתן לסכם בטבלה פשוטה את ההסתברות לניצחון מכל מצב לוח נתון.
טבלה זו נקראת Q-table:
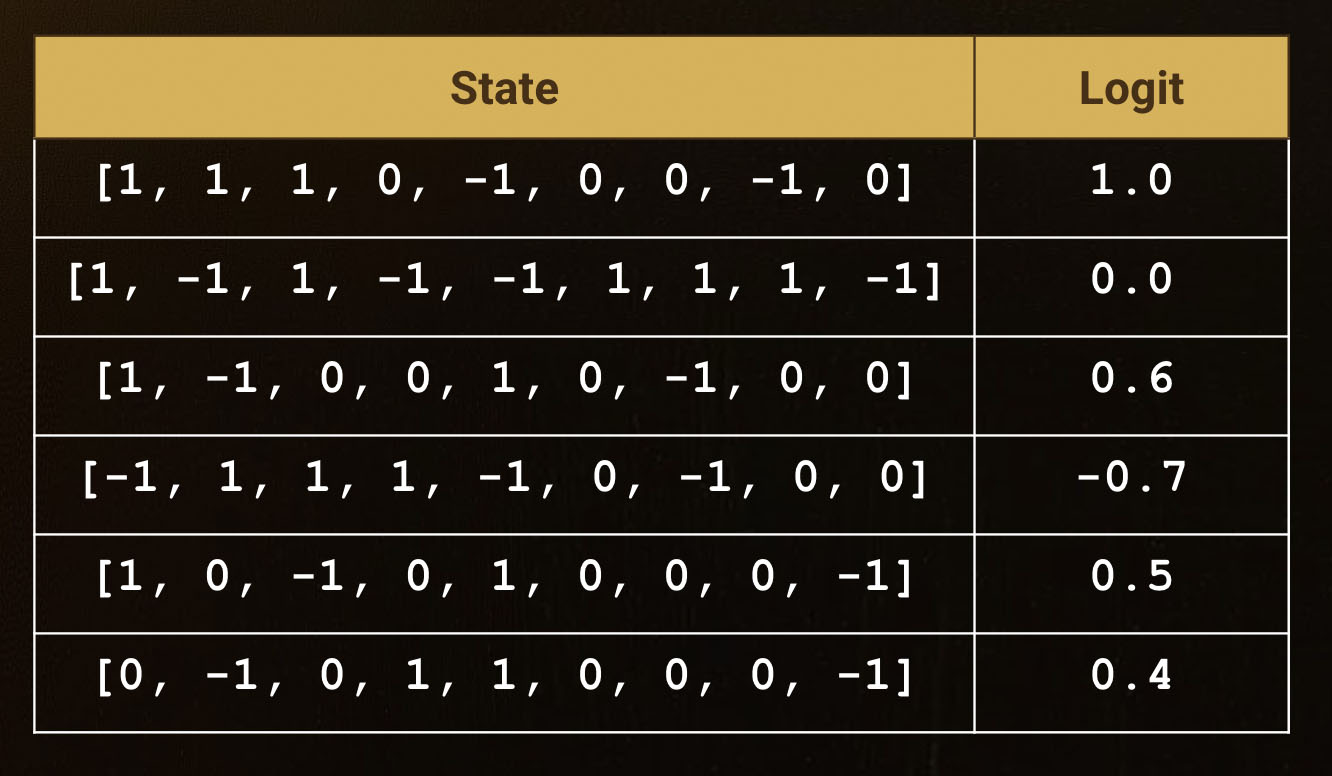
בטבלה זו, כל שורה מייצגת מצב לוח מסויים.
- עמודת ה State מייצגת את מצב הלוח: (1) הוא עיגול, (1-) הוא איקס, ו (0) הוא תא ריק.
- עמודת ה Logit מייצגת את ההסתברות לניצחון של Menace. לדוגמא:
- בשורה העליונה – מצב הלוח מייצג ניצחון של העיגול, לכן ההסתברות לניצחון היא 1.0
- בשורה השניה – מצב הלוח מייצג הפסד של העיגול, ולכן ההסתברות לניצחון היא 0.0.
- בשורות הבאות ניתן לראות הסתברויות שונות.
הטבלה היא מודל ה Machine Learning! ייצוג מתמטי של לוגיקה עסקית לפתרון בעיה כלשהי, אותה המכונה למדה בעצמה, ללא פיתוח מערכת מוגדרת של אסטרטגיה (אלגוריתם).
שימוש במודל
לאחר שהמודל שלנו מאומן – השימוש בו עובד באופן הבא:
בכל תור בו המכונה צריכה לבצע מהלך – היא הולכת לטבלה ובודקת: ״מתוך כל המצבים החוקיים הבאים – מהו מצב הלוח הבא, בו הסיכוי שלי לנצח הוא הגדול ביותר?״
לפי זה המכונה תחליט על המהלך הבא שלה עד הניצחון (או ההפסד).
אתגרים
זה נשמע מבטיח. אז למה לא כל מודל מודרני עובד כך?
ובכן – מכונת ה Menace של דון מיצ׳י היתה אבטיפוס של לימוד מכונה, והתוצר הוא טבלת-זיכרון.
המודל למעשה מורכב מזיכרון של מקרים ותגובות – ומכסה את כל מצבי המשחק האפשריים. זה יכול לעבוד טוב כשמדובר באיקס-עיגול, אבל במשחקים כמו שש בש, שחמט או Go – בהם מספר המהלכים האפשריים גדול משמעותית (לפחות 10 בחזקת 20…) – גודל הטבלה שתיווצר יהיה גדול מדי לאחסון וכבד מדי לתפעול, ותהליך האימון ייתארך עד אלפי שנים.
דרושה לנו כאן שיטת אימון אחרת, מודל מסוג אחר, כזה שיכול לחשוב בתבניות, ללמוד ״מהלכים״ ולא רק מצבים.
בקיצור – תלמיד שלומד עקרונות, ולא רק משנן שאלות ותשובות.
כאן נכנסות לתמונה רשתות הנוירונים, ונעסוק בכך במאמר נפרד.
המסע רק התחיל
כשדונלד מיצ׳י ישב במעבדה שלו ב-1961 ומילא בסבלנות את 304 קופסאות הגפרורים, הוא לא יכול היה לדמיין שהוא מניח את הבסיס לטכנולוגיה שתשנה את העולם. MENACE לא הייתה רק ניסוי מקסים – היא הייתה ההוכחה הראשונה שמכונות יכולות באמת ללמוד.
באותם ימים, עדיין לא היתה קיימת בעולם טכנולוגיית המחשוב הדרושה לאחסון ועיבוד כמויות הדאטה הדרושות לאימון מודלים כמו GPT או Gemini, ולמעשה – בעשרים השנים הבאות לא נעשתה עבודה משמעותית בתחום למידת המכונה.
אבל הכי מרתק בסיפור הזה זה לא רק מה שהוכח, אלא מה שהתגלה. כל מודל למידה – מהפשוט ביותר ועד למתקדם ביותר – נאבק עם אותם שלושה אתגרים בסיסיים:
- איך לזכור? MENACE פתרה את זה עם קופסאות. מודלים מודרניים פותרים את זה עם פרמטרים.
- איך להכליל? זה מה שהפריד בין איקס-עיגול לשחמט. זה מה שמפריד בין שינון לחשיבה אמיתית.
- איך לאזן בין ידע קיים לחקירה של דברים חדשים? השאלה הנצחית שכל אלגוריתם לימוד פותר בדרכו.
רשתות הנוירונים, שעליהן נדבר במאמר הבא, הן תשובה אלגנטית לשאלות הללו. אבל הן לא הפתרון היחיד, ובהחלט לא האחרון.
מה שמיצ׳יי הראה לנו זה שבלב של כל בינה מלאכותית, מתחת לכל השכבות הטכנולוגיות המורכבות, יושב עקרון פשוט: ניסיון, טעייה, ושיפור מתמיד.
השאלה שתעסיק אותנו בהמשך היא לא "איך מכונות לומדות?" – על זה כבר ענה מיצ׳י עם הקופסאות שלו. השאלה היא "איך אנחנו יכולים ללמד אותן לחשוב?"
במאמר הבא: רשתות נוירונים – איך מחקים את המוח האנושי, ולמה זה לא עובד כמו שחשבנו.
Stay Tuned!