

דמיינו רגע מערכת בינה מלאכותית שמבינה את העולם מבלי לתרגם אותו למילים. שרואה סרטון, קולטת את המשמעות, ויודעת לענות על שאלות – הכל מבלי לייצר אפילו מילה אחת בתהליך החשיבה. זה לא מדע בדיוני. זו טכנולוגיית בינה מלאכותית חדשה בשם "VL-JEPA", והיא עשויה לסמן את הסוף של עידן ה-LLM כפי שאנחנו מכירים אותו.
למה מודלי שפה של היום בעצם מבזבזים משאבים?
כשאתם שואלים מודל שפה מודרני "מה קורה אם אני מוריד את מתג האור למטה?", הוא עשוי לענות תשובות כמו:
- "האור יכבה"
- "החדר יהפוך חשוך"
- "המנורה תפסיק לפעול"
שלוש תשובות שונות לחלוטין מבחינת המילים, אבל זהות לחלוטין מבחינת המשמעות.
בשבילנו, בני האדם, זה טריוויאלי – אנחנו מיד מזהים שמדובר באותה תשובה בדיוק. אבל למודלי שפה גדולים (LLMs), אלו שלושה רצפי טוקנים שונים לגמרי, כמעט ללא חפיפה. במהלך האימון, המודל מושקע במשאבי מחשוב אדירים בלימוד ניסוחים, סגנונות כתיבה, ומבנים תחביריים – כל זה מבלי ששום דבר מזה באמת משנה את המשמעות של התשובה.
זה לא באג – זו בעיה מבנית.
גם מודלי VLM – Vision-Language Models מודרניים פועלים כך: הם מקבלים תמונה או סרטון, מקבלים שאלה, ומייצרים טקסט – טוקן אחר טוקן. כך עובדים כיתובים לתמונות, מענה על שאלות חזותיות, ורוב המודלים המולטימודליים הגדולים. הם מאומנים לחזות את המילה הבאה, ואז את המילה הבאה, ואז את המילה הבאה שוב.
הגישה הזו עובדת, בלי ספק. אבל היא גוררת שני מחירים כבדים:
- ראשית, המודלים נאלצים ללמוד דברים שלא משפיעים על נכונות התשובה. במקום להתמקד ברעיון עצמו, הם מתאמצים לדייק בניסוח המדויק, בבחירת מילים ספציפיות, במבנה המשפט – שום דבר מזה לא משנה את התוכן, אבל זה גוזל עצום מהמשאבים.
- שנית, יצירת טקסט טוקן-אחר-טוקן היא איטית ומסורבלת. במערכות שצריכות להבין מה קורה בזמן אמת – משקפי AR, רובוטיקה, ניווט אוטונומי – אתם לא יכולים לדעת מה המודל חושב עד שהוא מסיים לכתוב את כל המשפט. המשמעות מתגלה רק בסוף תהליך הדקודינג. זה מוסיף חביון (latency), שורף חישוב יקר, והופך כמעט לבלתי אפשרי לעדכן מידע באופן סלקטיבי.
וזה בדיוק המקום שבו VL-JEPA נכנס למשחק עם גישה שונה לחלוטין.
VL-JEPA: חשיבה ללא מילים
החשיבה האנושית מתבצעת במספר מישורים. באופן כללי ניתן לחלק את תהליכי החשיבה ל:
- חשיבה מילולית – דיבור פנימי. מהרגע שילד לומד לדבר הוא בשיח מתמיד עם עצמו, ובאופן הזה ״מלביש״ את תפיסת המציאות שלו במילים. ניתן לומר שיחידת הבסיס של המציאות בחשיבה זו היא האות הבודדת.
- חשיבה שאינה מילולית – אינטואיטיבית. כאן נוצרים דפוסים קוגניטיביים במוח, שעדיין לא הולבשו במילים, ומתגלים לאדם באופנים שונים: ב״אינטואיציה״, ״חוש שישי״, רגש מסויים, ״דז׳ה-וו״ ועוד תופעות. גם לחשיבה מילולית קודם החלק האינטואיטיבי, אלא שאז הוא עובר ״הלבשה״ במילים ואותיות, ומתגלה באופן מודע יותר לאדם החושב.
זה מה שמנסים לסמלץ עכשיו. במקום לחזות מילים, VL-JEPA חוזה משמעות ישירות.
השם המלא הוא VL-JEPA – Vision-Language Joint Embedding Predictive Architecture, ארכיטקטורת חיזוי משותפת של ראייה ושפה ב״מרחב הטמעות״. או-אה! השם נשמע מסובך, אבל הרעיון פשוט באופן מפתיע: במהלך האימון, המודל בכלל לא מנסה לייצר טקסט. במקום זאת, הוא לומד למפות קלט חזותי ושאלה טקסטואלית ישירות לייצוג סמנטי של התשובה – כמו הפעילות הנוירונית הקדומה במוח, שעדיין לא התלבשה במילים.
תחשבו על זה כך: במקום ללמוד "איך לכתוב תשובה נכונה", המערכת לומדת "איך נראית המשמעות של תשובה נכונה" – במרחב מתמטי רב-ממדי שנקרא ״מרחב הטמעות״ (embedding space).
איך זה בנוי?
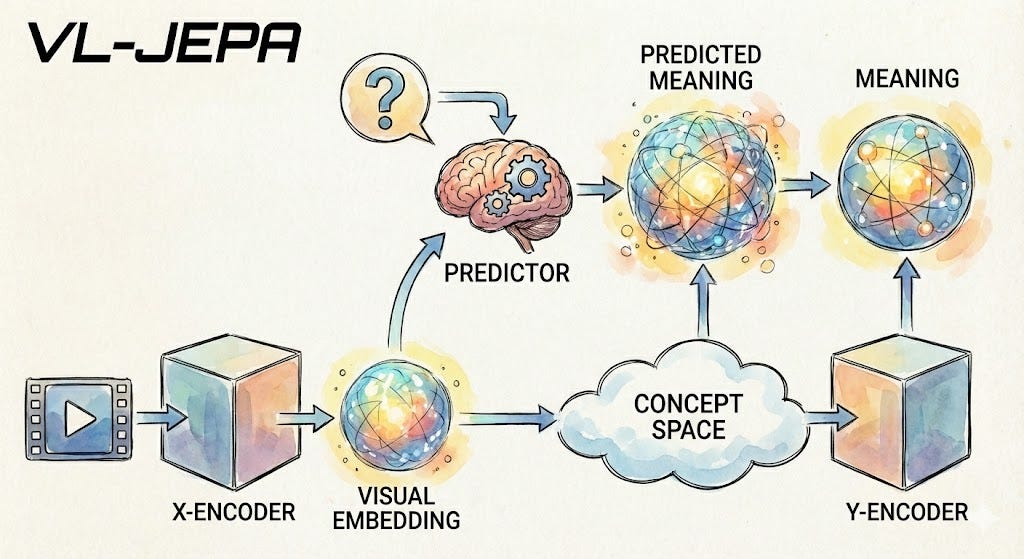
המערכת מורכבת מארבעה רכיבים מרכזיים, שכל אחד מהם ממלא תפקיד ברור:
- מקודד חזותי (Visual Encoder) – הרכיב הראשון לוקח תמונה או רצף פריימים מסרטון, ודוחס אותם לסט של ייצוגי-משמעויות מספריים, מה שנקרא ״הטמעות חזותיות״ (Visual Embeddings). תחשבו על אלה כעל "טוקנים חזותיים", רק שהם וקטורים רציפים במקום סימנים דיסקרטיים. במימוש הנוכחי, הם משתמשים ב-VJEPA-2, טרנספורמר ראייה שמאומן באופן עצמאי עם כ-304 מיליון פרמטרים, והוא נשאר קפוא (frozen) במהלך האימון.
- החזאי (Predictor) – זהו ליבת המערכת כולה. המודול הזה לוקח את ההטמעות החזותיות והשאלה הטקסטואלית, ומנסה לחזות איך אמורה להיראות הטמעת התשובה. הוא בנוי משכבות טרנספורמר שאותחלו "לשים לב" למשמעויות ולא לטקסט. הראייה והטקסט מקיימים אינטראקציה חופשית.
- מקודד (Encoder) – הרכיב הזה "מקודד" את התשובה הנכונה מטקסט לייצוג משמעותי-מספרי ("Embedding") במהלך האימון. זו בעצם מטרת הלמידה. חשוב להדגיש: הייצוג הזה אמור לתפוס את המשמעות של התשובה, לא את הניסוח.
- מפענח (Decoder) – וזה החלק המרתק: הרכיב הזה כמעט לא משתתף באימון בכלל. בזמן ההסקה (inference) – הרכיב נכנס לפעולה רק כשבאמת צריך טקסט קריא. רוב הזמן, המודל נשאר לגמרי במרחב ה-Embeddings.
התובנה המרכזית: מריבוי ניסוחים למשמעות אחת
הנה התובנה בבסיס של כל הגישה הזו:
במרחב המילים (הטוקנים), מספר תשובות תקינות יכולות להיות רחוקות זו מזו באופן קיצוני. "האור כבה", "החדר נעשה חשוך", "המנורה הפסיקה לפעול" – אלו רצפי טוקנים שונים לחלוטין.
במרחב המשמעויות (ה״הטמעות״), אותן תשובות יכולות לשבת קרוב זו לזו. הן חולקות משמעות, אז הן חולקות מיקום במרחב המתמטי.
זה הופך בעיית למידה מולטימודלית מבולגנת עם אינסוף ווריאציות לשוניות (multi-modal problem) לבעיה חלקה ומתומצתת עם משמעות אחת (single-mode problem). המודל כבר לא צריך לנחש איזה ניסוח אתם רוצים – הוא רק צריך להבין מה התשובה אומרת תכל׳ס.
בגלל זה, VL-JEPA לא צריך להריץ פיענוח שפה כבד במהלך האימון. הוא לא לומד איך לכתוב משפטים. הוא לומד איך לחזות סמנטיקה. והשינוי הזה לבדו חוסך כמות עצומה של עבודה מיותרת וכוח עיבוד.
התוצאות מדברות בעד עצמן
כדי לבדוק אם הרעיון באמת מחזיק מעמד, החוקרים ערכו ניסוי השוואתי על סרטוני וידאו, כאשר רוב הפרמטרים נשארו קבועים:
- אותו מקודד ויזואלי
- אותה רזולוציה
- אותו קצב פריימים
- אותה תערובת נתונים
- אותו גודל batch
- אותו מספר צעדי אימון
ההבדל היחיד: מה המודלים אומנו לחזות.
- מודל אחד הלך בנתיב הסטנדרטי – חיזוי טוקנים עם מודל שפה של מיליארד פרמטרים.
- מודל שני – גרסת VL-JEPA חזה הטמעות באמצעות חזאי של כ-500 מיליון פרמטרים. כלומר, למערכת המבוססת-הטמעות היו כמחצית מהפרמטרים הניתנים לאימון.
בתחילת האימון, שתי המערכות נראות דומות. אחרי כ-500,000 דגימות, הביצועים דומים בערך. אבל כשהאימון ממשיך, דפוס ברור מתחיל להתגלות:
VL-JEPA מתחיל להשתפר מהר יותר, והשיפור ממשיך.
אחרי 5 מיליון דגימות, הוא מגיע לדיוק של 14.7 (במדד Cider – מטריקת איכות לכיתובי וידאו) בזמן שהמודל המבוסס-טוקנים עדיין ב-7.1 בערך.
דיוק הסיווג קופץ לכ-35% עבור VL-JEPA לעומת כ-27% עבור המודל הלשוני. והפער לא נסגר מאוחר יותר. ב-15 מיליון דגימות, ההבדל נשאר. VL-JEPA ממשיך ללמוד ביעילות רבה יותר, אפילו עם פחות פרמטרים.
זה לא טריק של טיונינג. זה יתרון מבני.
הפתעה בזמן ריצה: דקודינג סלקטיבי
הסיפור לא נעצר ביעילות האימון. בזמן הסקה (inference) הגישה הזו מרשימה אפילו יותר! במיוחד עבור וידאו.
מכיוון ש-VL-JEPA מייצר זרם רציף של הטמעות סמנטיות, היא תומכת במשהו שנקרא selective decoding – דקודינג סלקטיבי. במקום לייצר טקסט במרווחי זמן קבועים, אתם עוקבים אחרי איך ההטמעות משתנות לאורך זמן. אם המשמעות נשארת יציבה – אתם לא מפענחים כלום. אם יש שינוי סמנטי משמעותי – אז אתם מפענחים.
הם בודקים את זה על סרטונים פרוצדורליים ארוכים מ-EgoExo4D. סרטונים אלה נמשכים בממוצע כ-6 דקות כל אחד, ומכילים בערך 143 הערות פעולה לסרטון. דקודינג טקסט הוא החלק היקר, אז המטרה היא לשחזר את רצף ההערות תוך מזעור מספר פעולות הדקודינג.
הם משווים שתי אסטרטגיות:
- Uniform decoding – טקסט מיוצר במרווחי זמן קבועים
- Embedding-guided decoding – זרם ההטמעות מקובץ לסגמנטים קוהרנטיים סמנטית ומפוענח פעם אחת לכל סגמנט
התוצאה נקייה: כדי להשיג ביצועים דומים ל-uniform decoding בקצב של דקודינג אחד לשנייה, VL-JEPA צריך ״לפענח״ (להלביש את המחשבה במילים) רק פעם אחת בכל 2.85 שניות בערך. זוהי הפחתה של פי 2.85 בערך בפעולות דקודינג, עם ביצועים דומים.
בלי טריקים מתוחכמים של זיכרון, בלי אקרובטיקה של KV cache. זו פשוט תוצאה של עבודה במרחב סמנטי.
זה חשוב במיוחד למערכות זמן אמת כמו משקפיים חכמים, רובוטיקה, ניווט או תכנון חי – מקומות שבהם חביון (latency) ועלות חישוב באמת משנים.
ריבוי שימושים, ארכיטקטורה אחת
יתרון מרכזי נוסף הוא מולטי-מודליות.
VL-JEPA יכול לטפל ביצירה (generation), סיווג (classification), אחזור (retrieval), ומענה – על שאלות חזותיות (discriminative VQA) – הכל באמצעות אותה ארכיטקטורה. אין ראשי משימות ייעודיים, אין מודלים נפרדים.
- עבור סיווג אוצר מילים פתוח – תוויות מועמדות מקודדות ל-Embeddings ונבדקות מול התשובה החזויה. ההתאמה הקרובה ביותר מנצחת.
- עבור אחזור טקסט-לוידאו – שאילתת הטקסט מקודדת וסרטונים מדורגים לפי דמיון.
- עבור VQA (Visual Question Answering) – כל התשובות המועמדות הופכות ל-Embeddings, והקרובה ביותר נבחרת.
תוצאות מפתיעות ב-VQA והבנת העולם
בניסוי world modeling – מודלינג העולם, נבדק האופן בו המודל יוצר את תמונת המציאות שהוא ״רואה״.
המודל רואה תמונה התחלתית ותמונה סופית, וצריך לבחור איזו פעולה גרמה למעבר – מתוך ארבעה קליפים מועמדים. זה קרוב יותר להבנת סיבתיות פיזית מאשר ייצור שפה.
מגיע ל-65.7% דיוק, state-of-the-art חדש. הוא עלה על מודלי ראייה-שפה גדולים יותר, ואפילו ניצח מודלי שפה מתקדמים כמו GPT-4o, Claude 3.5, ו-Gemini 2 – שמסתמכים על כיתוב והנמקה מבוססת-טקסט.
התוצאה הזו חשובה. היא מציעה שחיזוי ישיר של סמנטיקה חבויה יכול להיות יעיל יותר מלתאר את העולם במילים ולהסיק על פניהן אחר כך.
מה זה אומר על העתיד של AI?
VL-JEPA לא מנסה להחליף מודלי שפה בכל מקום. משימות כמו Deep Reasoning, שימוש בכלים ותכנון בסגנון Agent – עדיין מעדיפים מערכות מבוססות-טוקנים.
אבל לבעיות כבדות-תפיסה – במיוחד אלה הכוללות וידאו, קלט זמן-אמת והבנה רציפה של העולם – הגישה הזו מתאימה באופן טבעי.
היא מזיזה את מרכז הכובד מהשפה למשמעות. מילים הופכות לאופציית פלט, לא המנגנון המרכזי של אינטליגנציה.
והשינוי הזה הוא מה שגורם לעבודה הזו להרגיש כמו יותר מסתם איטרציה נוספת של מודל. זה מרגיש כמו הצעד הבא – מה שבא אחרי עידן ה-LLM.
כי אולי, רק אולי, אינטליגנציה אמיתית לא צריכה לעבור דרך מילים כדי להבין את העולם. אולי היא יכולה פשוט לראות, לקלוט, ולדעת – ישירות.